正所谓前人栽树,后人乘凉。
1. R语言简介
1.1 R语言是什么
R 是一个有着统计分析功能及强大作图功能的软件系统,是由新西兰奥克兰大学统计学系的 Ross Ihaka 和 Robert Gentleman 共同创立,可能是因为两人首字母都是R所以就叫R语言。R语言是一门统计语言,天生就不同于其他的编程语言。R语言封装了各种基础学科的计算函数,我们在R语言编程的过程中只需要调用这些计算函数,就可以构建出面向不同领域、不同业务的、复杂的数学模型。
掌握R语言的语法,仅仅是学习R语言的第一步,要学好R语言,需要你要具备基础学科能力(初等数学,高等数学,线性代数,离散数学,概率论,统计学) + 业务知识(金融,生物,互联网) + IT技术(R语法,R包,数据库,算法) 的结合。所以把眼光放长点,只有把自己的综合知识水平提升,你才真正地学好R语言。
换句话说,一旦你学成了R语言,你将是不可被替代的。
1.2 R语言有什么用
- 统计分析:包括统计分布,假设检验,统计建模
- 金融分析:量化策略,投资组合,风险控制,时间序列,波动率
- 数据挖掘:数据挖掘算法,数据建模,机器学习
- 互联网:推荐系统,消费预测,社交网络
- 生物信息学:DNA分析,物种分析
- 生物制药:生存分析,制药过程管理
- 全球地理科学:天气,气候,遥感数据
- 数据可视化:静态图,可交互的动态图,社交图,地图,热图,与各种Javascript库的集成核心是统计分析,分类是数据处理,机器学习,文本挖掘,量化投资, 高级绘图
1.3 R语言环境搭建
R语言环境安装
https://www.r-project.org/ **1.3.2 R studio安装**
https://www.rstudio.com/
1.3.3 R依赖包安装
>install.packages(“package_name”): 安装
>library(“package_name”): 加载使用
>detach(“package_name”, unload = TRUE): 卸载
>remove.packages(“package_name”): 从本地删除
>update.packages(oldPkgs = “package_name”): 升级
1.3.4 查找R包安装位置
.libPaths()
1.3.5 定位文件、设置文件位置
getwd()
setwd()
2. R 语言基础
2.1 基本运算:
算术运算: + - * \ ^
比较运算: > < >= <= == !=
逻辑运算: 与,或,非
函数运算: log2(x) log10(x) exp(x) sin(x) tan(x) abs(x) sqrt(x)
2.2 数据结构

2.2.1 向量
向量是多个值的集合,根据变量类型的不同可以分为数值型向量,字符型向量和逻辑向量。
内置向量: letters, LETTERS, month.abb, month.name;
向量的创建: c(), seq(), rep();
向量索引: [];
向量元素命名: names()。
2.2.2 矩阵和数组
矩阵可以理解为多行多列的表格(更高维度的向量),通常,列表示变量,行表示个体或者观测值。
构造矩阵可以通过matrix()函数;
矩阵(matrix) 是一种特殊的向量, 包含两个附件的属性,即是行数和列数;
矩阵常用于线性代数;
矩阵必学包: Matrix。
举例说明:
nrow() and ncol()可以返回矩阵的行数和列数,rownames()和colnames()可以返回或者设置矩阵的行名和列名;
从一个矩阵中提取子集的方法和向量类似,只不过分为行和列两个参数,行和列各自的提取方式和向量相同,[]内第一个参数行位置,第二个参数代表列位置;
rowSums() colSums()可以用来为矩阵的行列分别求和,rowMeans() 和 colMeans()则用来计算均值;
如果想使矩阵的行列互换,只需要使用t()函数即可。
2.2.3 因子
在R中,变量可以是连续型变量,名义型变量(无需:a,b,c)和有序变量(上,中,下)。名义型变量和有序变量也叫作因子,通过factor()函数可以设置因子,并以数组形式储存。
2.2.4 数据框(重点)
数据框类似于矩阵,是特殊的列表,每一列可以是不同的模式,类似于Excel。
内置数据集: library(help = “datasets”);
创建数据框: data.frame()。
2.2.5 列表
list(),选取元素使用的是[[]]。
列表就像一个晾衣架,里面可以挂着向量、数组、数据框。
2.3 外部数据导入导出
2.3.1 Excel表格到R语言转换
a = read.table('item.txt', header = T, sep = '\t')
b = read.table('item.txt', comment.char = '!', header = T, sep = '\t') # 带感叹号的不读取
write.csv(data, file = 'data.csv', row.names = FALSE)
d = read.csv('item.csv',sep=',',header= T)
3. R 语言进阶
3.1 条件控制if else
3.1.1 逻辑判断
if (condition) {
expr
}
3.2 循环 while for
3.2.1 while循环
while (condition) {
expr
}
3.2.2 break
略。
3.2.3 for循环
primes <- c(2, 3, 5, 7, 11, 13)
# loop version 1
for (p in primes) {
print(p)
}
# loop version 2
for (i in 1:length(primes)) {
print(primes[i])
}
3.3 函数(apply、lapply、sapply)
首先我们引入一个问题
R 需要编程么? 不!大多数时候不需要,因为 R 有很多函数和包,而且每天都在增加,我们用的一般方法和函数都可以在 R 自带包中找到。
下面主要介绍一下apply(),lapply(),sapply()
3.3.1 apply(X, MARGIN, FUN, …)
其中X为一个数组;MARGIN为一个向量(表示要将函数FUN应用到X的行还是列),若为1表示取行,为2表示取列,为c(1,2)表示行、列都计算。
>ma <- matrix(c(1:4, 1, 6:8), nrow = 2)
>ma
>apply(ma, c(1,2), sum)
>apply(ma, 1, sum)
>apply(ma, 2, sum)
注意行列都计算等同于每个元素都计算
比如:
apply(ma, c(1,2), sqrt)
等同于
sqrt(ma) 这是**向量化计算**(速度很快)
3.3.2 lapply(X, FUN, …)
lapply返回的是列表。
# The vector pioneers has already been created for you
pioneers <- c("GAUSS:1777", "BAYES:1702", "PASCAL:1623", "PEARSON:1857")
# Split names from birth year
split_math <- strsplit(pioneers, split = ":")
# Take a look at the structure of split_math
str(split_math)
# Convert to lowercase strings: split_low
split_low <- lapply(split_math,tolower)
# Take a look at the structure of split_low
str(split_low)
3.3.3 sapply(X, FUN, …)
注意和lapply的区别,返回值不一样
# create temp
temp <- list(c(3,7,9,6,-1),
c(4,8,3,-1,-3),
c(1,4,6,2,-2),
c(5,7,9,4,2),
c(3,7,9,6,-1),
c(-3,5,8,9,4),
c(6,9,12,13,5))
# Use lapply() to find each day's minimum temperature
lapply(temp,min)
# Use sapply() to find each day's minimum temperature
sapply(temp,min)
# Use lapply() to find each day's maximum temperature
lapply(temp,max)
# Use sapply() to find each day's maximum temperature
sapply(temp,max)
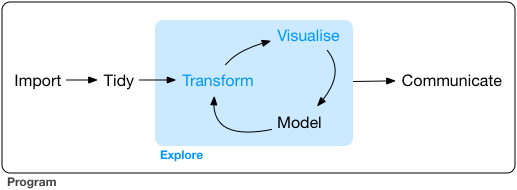
4. 数据分析流程(重点中的重点)
4.1 向量篇
4.4.1 内置向量
letters # 小写字母
LETTERS # 大写字母
month.abb # 月份缩写
month.name # 月份全称
4.4.2 创建向量
>c("ding", "li")
>1:10
>seq(1,10, 2) # 每隔2个数字
>?seq
>rep(c("a","b","c"), 2) # 重复
4.4.3 向量索引
>letters[10]
>letters[1:10]
>letters[seq(1,10,2)]
>letters[seq(1,10,2) > 2]
4.4.4 向量运算
>1:10 + 11:20
>11:20 - 1:10
>11:20 %% 2 == 0
4.4.5 变量赋值
>myname <- c("ding", "li")
>c("ding", "li") -> yourname
4.2 矩阵篇
>library(Matrix)
>m <- matrix(1:20, nrow = 5, ncol =4 ) # 创建矩阵
>Matrix::rowSums(m) #行和
>Matrix::rowMeans(m) #行均值
>Matrix::colSums(m) #列和
>Matrix::colMeans(m) #列均值
4.3 设置项目路径
getwd()
>setwd("/Users/zgxu/Desktop/R语言基础/")
4.4 文件读取
数据存储无非两种方式: 二进制, 文本;
核心函数 read.table;
其他函数 read.xxx。
>options(stringsAsFactors = FALSE)
>expr_df <- read.csv("exprData.csv", header = FALSE
)
>expr_df[1:10,1:6]
>meta_data <- read.table("metadata.txt",sep = "\t", header = TRUE)
>head(meta_data)
>gene_names <- readLines(con = "gene_name.txt")
>head(gene_names)
4.5 数据框篇
is.data.frame(expr_df) # 判断是否是数据框
dim(expr_df) # 行列数
4.5.1 变量重命名
>row.names(expr_df) <- gene_names # 行名
>colnames(expr_df) <- meta_data$Run #列名
>head(expr_df)
4.5.2 根据index进行命名
>new_name <- paste(meta_data$dex,rep(c(1,2,3,4),each=2), sep = "_") # 合并字符串
>colnames(expr_df) <- new_name
>head(expr_df)
4.5.3 创建新变量: 根据现有值进行变换
形式: 变量名 <- 表达式。
案例1: 获取一些关于基因和样本的元信息
>total_count_per_gene <- rowSums(expr_df) #每个基因的表达量
>total_count_per_sample <- colSums(expr_df) # 每个样本的表达量
案例2: 根据深度深度进行标准化
>new_df <- expr_df / rep(total_count_per_sample, each=nrow(expr_df)) * 1000000
4.5.4 类型转换
isis..xxxx 用于判断, as.xxxx用于转换
>is.matrix(new_df)
>expr_matrix <- as.matrix(new_df)
>is.matrix(expr_matrix)
4.5.5 数据排序
案例1: 按照基因的表达量总数对表达矩阵排序
>df_ordered <- expr_df[order(total_count_per_gene),] # 升序
>df_ordered <- expr_df[order(total_count_per_gene, decreasing = T),] # 降序
4.5.6 数据集合并
案例1:增加样本元信息
>cbind(meta_data, total_count_per_sample) # 增加列, column
>meta_data$total_count_per_sample <- total_count_per_sample # 增加列
案例2: 增加每个样本的总数行
>df_tmp <- rbind(expr_df, total_count_per_sample) # 增加行, row
>tail(df_tmp)
4.5.7 数据集取子集
案例1: 提取表达量前10的基因
>top_10 <- df_ordered[1:10, ]
案例2:过滤低表达的基因
>gene_to_filter <- total_count_per_gene > 10
>df_filterd <- expr_df[gene_to_filter, ]
>dim(df_filterd)
案例3: 随机抽样
>set.seed(19930831)
>df_sample <- expr_df[sample(1:nrow(expr_df), 1000, replace = FALSE ), ]
>dim(df_sample)
5. R的可视化介绍
R绘图工具库中核心是grDevices包,该包被称为绘图引擎。该包提供了一些列R中的基本绘图参数,几乎所有的R绘图应用都是用了grDevices包。
在绘图引擎上直接搭建了大量包:graphics包和grid包。这两个包代表着两个巨大的不相容的绘图系统,将R的绘图功能从主题上分割成了两个不同的部分。
绘图有两种思想:纸笔模型和图形语法。
5.1 R绘图系统的简单介绍
5.1.1 图形语法
一张统计图形就是从数据到集合对象(geometric object, 缩写为 geom,包括点、线、条形等)的图形属性(aesthetic attributes, 缩写为 aes, 包括颜色、形状、大小等)的一个映射。
此外,图形中还可能包含数据的统计变换(statistical transformation, 缩写为 stat),最后绘制在某个特定的坐标系(coordinate system, 缩写为 coord)中,而分面(facet, 指将绘图窗口划分为若干个子窗口)则可以用来生成数据中不同子集的图形”。
有了语法之后,图形不在被形状束缚,作图进入艺术创作的状态,限制我们的不是技术,而是想象力。
5.1.2 图层的概念(layer)
根据百度百科,图层的定义是:
图层就像是含有文字或图形等元素的胶片,一张张按顺序叠放在一起,组合起来形成页面的最终效果
做出基本的图形后,根据需要不断地添加图层,每一个图层的元素都可以更改,甚至我们可以把不同数据集的数据融合在一张图上。
5.2 gglot2极简入门
数据,图形属性,几何对象,主题,分面,统计变换
>ggplot(mtcars, aes(x = wt, y = mpg, color = disp)) +
geom_point()
# mtcars是数据
# aes是图形属性,包括颜色,形状,大小等
# eom_point()是点,线,条形等几何对象,没有散点图,直方图这种具体的概念。
# 有了这三个元素,我们就已经可以开始作图 如果需要添加元素,+号即可搞定,如下:
ggplot(diamonds, aes(x = carat, y = price))+
geom_point()+
geom_smooth()
# geom_point()散点图之上可以添加geom_smooth() 平滑曲线
6. 使用Bioconductor包分析基因芯片数据
见另一篇博客:使用R语言分析Microarray芯片数据