资料来源:公众号:育种数据分析之放飞自我
1.前言
–geno筛选个体;–mind筛选SNP
GWAS分析时,拿到基因型数据,拿到表型数据,要首先做以下几点:
- 查看自己的表型数据,是否有问题
- 查看自己的基因型数据,是否有问题
然后再进行建模,得到显著性SNP以及可视化结果。
清洗数据的时间占80%的时间,有句话这样讲:“Garbage in, Garbage out(垃圾进,垃圾出)”,所以清洗数据非常重要。
「为何对缺失数据进行筛选?」
无论是测序还是芯片,得到的基因型数据要进行质控,而对缺失数据进行筛选,可以去掉低质量的数据。如果一个个体,共有50万SNP数据,发现20%的SNP数据(10万)都缺失,那这个个体我们认为质量不合格,如果加入分析中可能会对结果产生负面的影响,所以我们可以把它删除。同样的道理,如果某个SNP,在500个样本中,缺失率为20%(即该SNP在100个个体中都没有分型结果),我们也可以认为该SNP质量较差,将去删除。当然,这里的20%是过滤标准,可以改变质控标准。下文中的质控标准是2%。
2.plink数据格式转化
数据使用上一篇的数据,因为数据是plink的bfile格式,二进制不方便查看,我们将其转化为文本map和ped的格式。
plink --bfile HapMap_3_r3_1 --recode --out test
结果生成:test.map test.ped
2.查看基因型个体和SNP数量
wc -l test.map test.ped
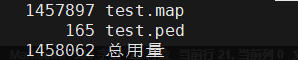
可以看出,共有165个基因型个体,共有1447897个SNP数据。
「预览一下ped文件:」
「预览一下map文件:」
3.查看一下个体缺失的位点数,每个SNP缺失的个体数
–missing: Sample missing data report written to plink.imiss, and variant-based missing data report written to plink.lmiss.
结果生成两个文件,分别是一个个体ID上SNP缺失的信息,另一个是每个SNP在个体ID中缺失的信息。
- 个体缺失位点的统计在plink.imiss中
- 单个SNP缺失的个体数在plink.lmiss中
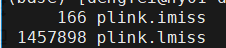
3.1 个体缺失位点统计预览:
第一列为家系ID,第二列为个体ID,第三列是否表型缺失,第四列缺失的SNP个数,第五列总SNP个数,第六列缺失率。
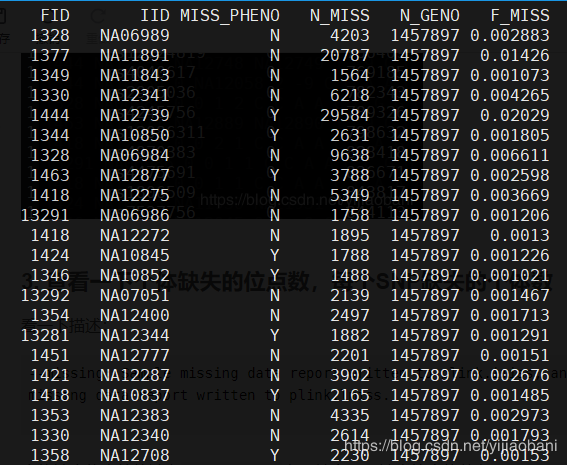
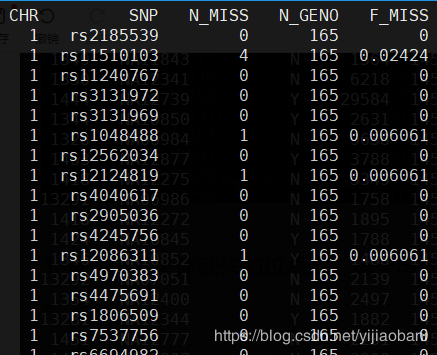
3.2 SNP缺失的个体数文件预览:
第一列为染色体,第二列为SNP名称,第三列为缺失个数,第四列为总个数,第五列为缺失率。
3.3 单个位点缺失率和基因型个体缺失率统计
使用R语言做直方图。下面代码的意思是读取这两个文件,然后用频率的那一列作图,将图保存为pdf输出。
indmiss<-read.table(file="plink.imiss", header=TRUE)
snpmiss<-read.table(file="plink.lmiss", header=TRUE)
# read data into R
pdf("histimiss.pdf") #indicates pdf format and gives title to file
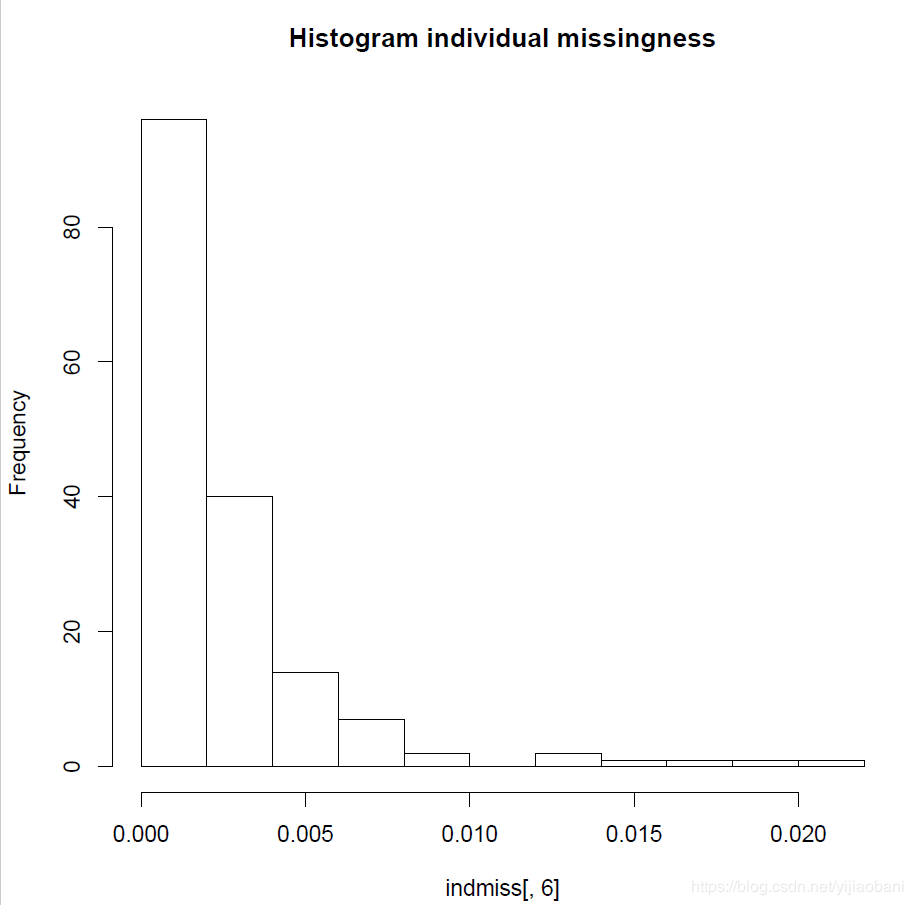
hist(indmiss[,6],main="Histogram individual missingness") #selects column 6, names header of file
pdf("histlmiss.pdf")
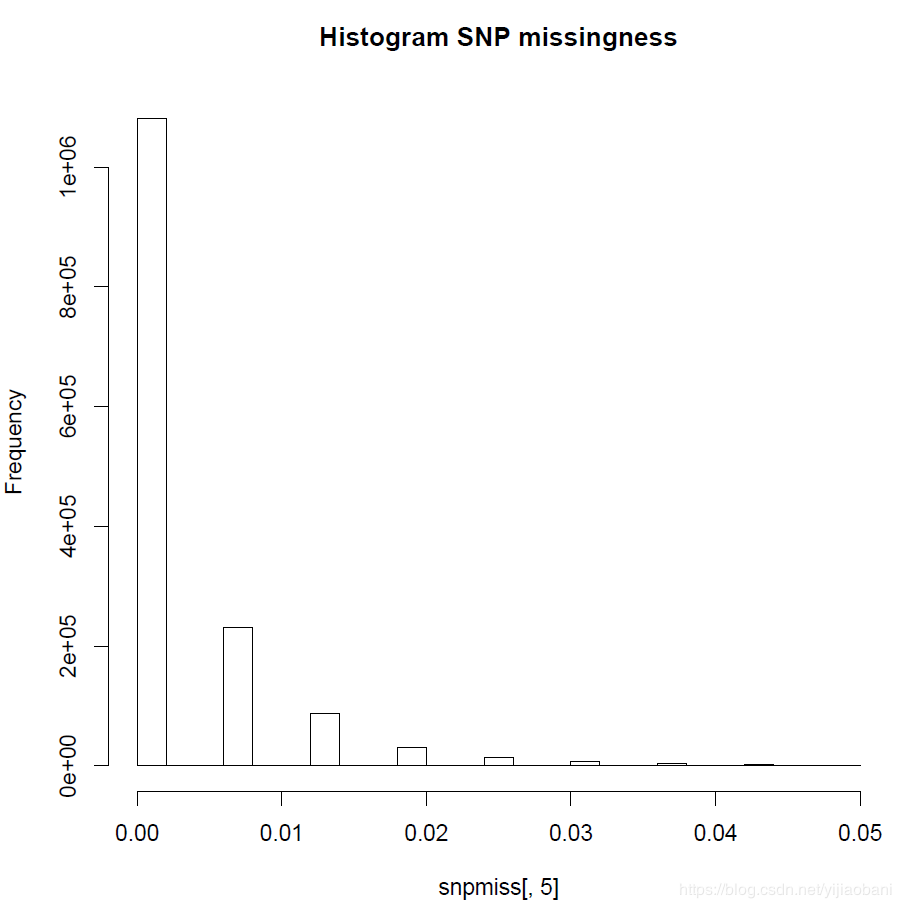
hist(snpmiss[,5],main="Histogram SNP missingness")
dev.off() # shuts down the current device
因为,当前目录已经有hist_miss.R脚本,所以可以直接在目录下运行下面代码,会生成两个pdf文件。
Rscript hist_miss.R
(1)单个位点缺失率统计图:
(2)基因型个体缺失率统计图:
4.对个体及SNP缺失率进行筛选
- 如果一个SNP在个体中2%都是缺失的,那么就删掉该SNP,参数为:–mind 0.02
- 如果一个个体,有2%的SNP都是缺失的,那么就删掉该个体,参数为:–geno 0.02
4.1 对个体缺失率进行筛选
先过滤个体缺失率高于2%的SNP:
plink --bfile HapMap_3_r3_1 --geno 0.02 --make-bed --out HapMap_3_r3_2
转化为map和ped的形式:
plink --bfile HapMap_3_r3_2 --recode --out test
查看一下过滤后的行数。
#之前的为:
1457897 test.map
165 test.ped
现在的为:
1430443 test.map
165 test.ped
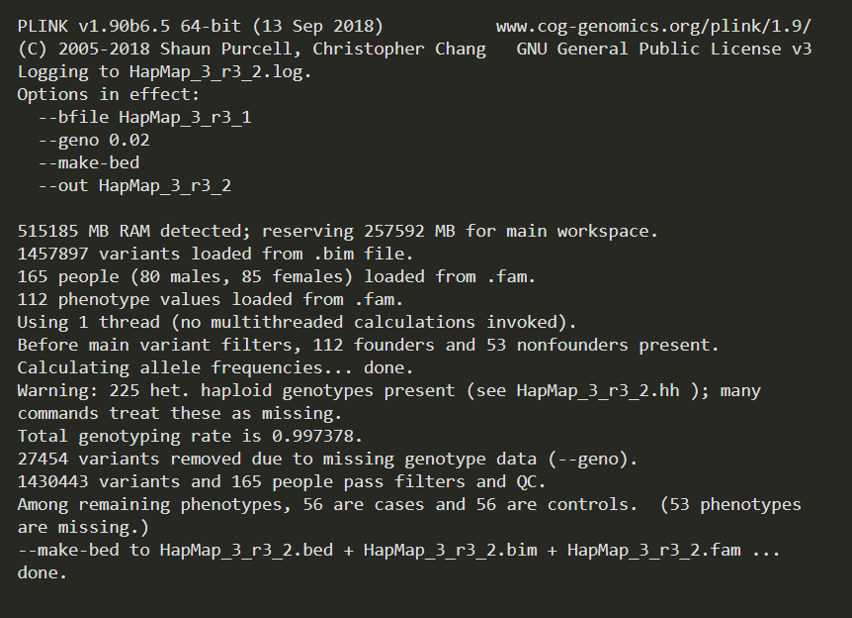
从日志中可以看出,过滤了27454个位点。
4.2 对SNP缺失率进行筛选
过滤SNP缺失率高于2%的个体:
plink --bfile HapMap_3_r3_2 --mind 0.02 --make-bed --out HapMap_3_r3_3
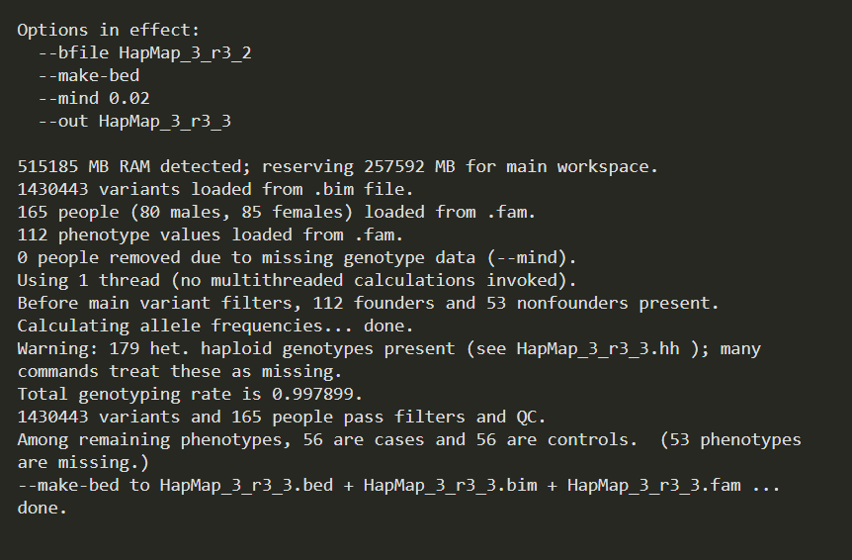
从日志中可以看出,0个个体被过滤,有165个个体的130443个SNP pass。
5.同时对个体和SNP的缺失率进行筛选
两步合在一起,即过滤位点,又过滤个体:
plink --bfile HapMap_3_r3_1 --geno 0.02 --mind 0.02 --make-bed --out HapMap_3_r3_5
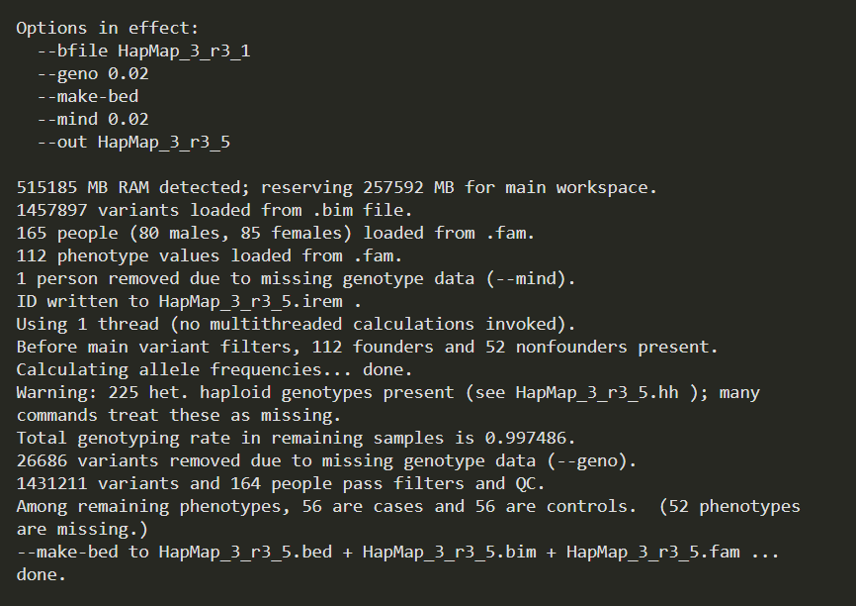
从日志中可以看出,两者最终结果是一样的。